Haproxy reloads and HTTP keep-alive
This December 2019 production outage is brought to you by Haproxy and HTTP keep-alive.
The setup
At a customer, we have a clustered Alfresco setup with docker containers. This is a high-availability setup with two nodes. Clients connect through an externally managed F5 loadbalancer, which then connects to one of our Haproxy loadbalancers.
Under normal conditions, Haproxy sends traffic to both Alfresco servers. The setup with two levels of loadbalancers is made because we want to be able to disable an Alfresco backend during deployments.
graph LR
client --> f5-loadbalancer
f5-loadbalancer --> haproxy1
f5-loadbalancer --> haproxy2
subgraph node1
haproxy1 --> alfresco1
end
subgraph node2
haproxy2 --> alfresco1
haproxy1 --> alfresco2
haproxy2 --> alfresco2
end
Because Alfresco is running in docker containers, they don’t have fixed IP addresses that can be put in the Haproxy configuration.
This is one of the reasons why we have a consul cluster running at each client. A helper process will grab the containers IP addresses from consul, then writes the configuration for haproxy and sends a SIGUSR2 to haproxy, which will cause it to reload its configuration.
A problem
One fateful night, Alfresco needs to be shut down for a couple of hours for a scheduled database maintenance operation. After this database maintenance, Alfresco is started up again. A manual sanity check indicates that both Alfresco nodes are back up and running and everything is fine.
However, not everything was fine. In the morning, we receive a phone call that requests to Alfresco are failing with HTTP 503 Service Unavailable. After restarting haproxy, these errors subdue.
Investigation
As the reader of this blog might already have noticed, I do not like it when things go badly and I don’t know what caused the issue. After all, the only way to prevent the same issue from wreaking havoc again is to find the root cause and to eliminate it.
Since we already restarted some services to recover as fast as possible, some amount of evidence is gone now. But thanks to Kibana, we still have a good amount of data to work with after the fact.
Finding the culprit
We make a graph of the haproxy access logs, where we graph HTTP 503 responses (red) and all other responses (green).
Since only some requests were answered with an error, we try to find out what’s wrong exactly by splitting the graphs based on which node the haproxy server runs on, and which backend haproxy is sending to.
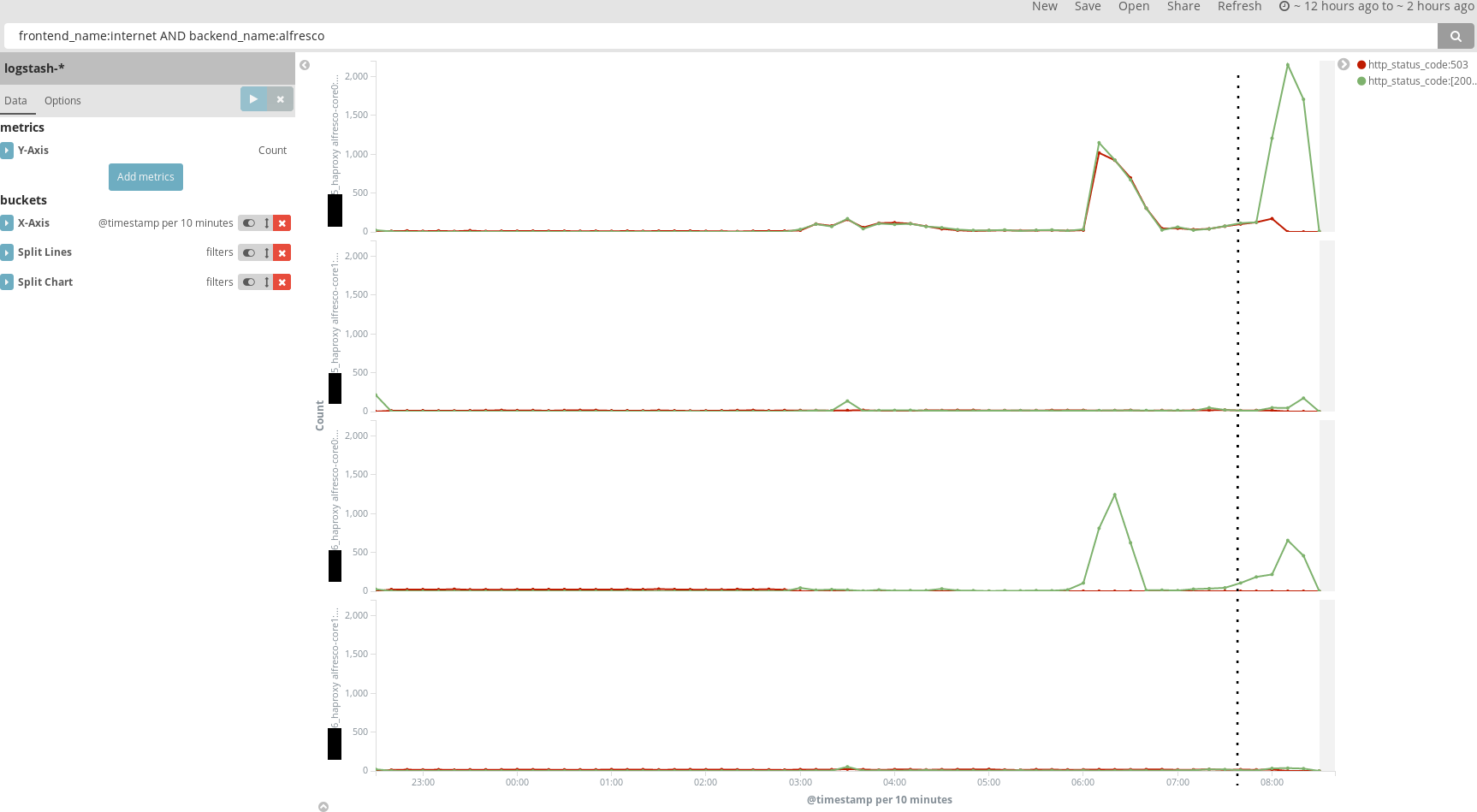
These graphs look very strange in two ways:
- Traffic appears to be only sent to one Alfresco node.
- Traffic of the one haproxy server to one backend is returning a 503 error half of the time.
It is expected that traffic is only sent to one Alfresco node. Haproxy is configured to use sticky loadbalancing based on source IP. Since all traffic comes from the F5 loadbalancer, there is only one source IP, and everything is sent to the same (first) backend server.
However, that half of the requests to one haproxy server and backend are returning a 503 error is quite unexpected. We know that that haproxy server and that Alfresco backend are running on the same server, so network issues can be excluded as a cause.
Things that we already encountered before that return 503 errors are:
- Haproxy configuration is not updated when the Alfresco container is recreated and changed IP address, resulting in haproxy not being able to reach the Alfresco backend
- Docker overlay networking is broken, and containers can’t reach each other
- Alfresco healtcheck failed on both nodes, and both nodes were removed from the haproxy configuration
None of these cases explains why some requests are succeeding and others failing, and why the situation recovered after haproxy was restarted.
Into the failing haproxy container
Looking at the logs of that haproxy server in kibana showed something strange:
<134>Dec 20 05:50:56 haproxy[45085]: xxx.xxx.xxx.194:2133 [20/Dec/2019:05:50:56.643] internet-xxx.xxx.xxx.82 alfresco/alfresco-core0 0/0/1/123/129 200 63108 - - --NN 4/4/0/1/0 0/0 "GET /alfresco/ HTTP/1.1"
<134>Dec 20 05:50:56 haproxy[31628]: xxx.xxx.xxx.196:38412 [20/Dec/2019:05:50:49.099] internet-xxx.xxx.xxx.82 alfresco/alfresco-core0 0/5518/-1/-1/7523 503 212 - - SCNN 1/1/1/0/2 0/0 "GET /alfresco/ HTTP/1.1"
There are many lines similar to these, where about half of these requests succeed, and the other half fail.
One thing that we notice when looking at the log messages is that failures are consistently logged by haproxy[31628] and successful requests are logged by haproxy[45085]. Failing requests are also always coming from the same set of IPs and ports.
In normal circumstances, there should only be one haproxy worker process that handles requests, as nbproc is set to 1. The fact that 2 worker processes are running at the same time is an indication that something went wrong.
How haproxy reloads its configuration
Like many *nix daemons, haproxy implements a reload mechanism that allows loading a new configuration without stopping and starting the server. In haproxy, there are multiple ways the reload mechanism works, depending on the mode in which haproxy is started. We are using the master-worker mode, so I will only describe that mechanism here.
The reload starts when the master process receives a SIGUSR2 signal. The master process will then re-exeute itself with the -sf parameter, followed by PIDs of all its worker processes.
Next, the master process will start listening on the configured ports with SO_REUSEPORT, so it can bind in parallel with the existing old worker processes.
New worker processes are started by the master process. They inherit the listening socket and start serving new requests.
Finally, the master process sends the SIGUSR1 signal to all the old workers (listed in the -sf parameter). The old workers will stop themselves once they have finished processing all existing connections.
sequenceDiagram
activate Old worker
User-->>Haproxy master: SIGUSR2
activate Haproxy master
Haproxy master ->> Haproxy master: Re-execute itself
Note over Haproxy master: Start listening on ports
Haproxy master ->> New worker: Execute new worker
activate New worker
Haproxy master --x Old worker: SIGUSR1
Note over Old worker: Stop after processing all pending requests
deactivate Old worker
deactivate New worker
Why master-worker is problematic with multiple levels of loadbalancers
This is fine when users enter directly through haproxy. It does not take that long for a normal user to close their connection, as browsers will typically only keep a connection alive for a couple of minutes after the last request is made through that TCP connection.
However, in the case that there is another layer of loadbalancers in front, that loadbalancer can keep sending requests from different clients over the same TCP connection, keeping the process alive indefinitely, and thus keeps sending clients to a no longer existing backend IP. The F5 loadbalancer healthcheck does not detect this problem, because it is sent with a new TCP connection every time.
Solving the problem
An initial fix consisted of configuring hard-stop-after, to ensure that worker processes will exit after some time.
This way, we still get all the benefits from a soft reload, not dropping all user connections immediately, but we limit the damage that is done when TCP connections are kept alive for a very long time and keep their connections to a stale worker process.
A couple of months later, we embarked on a mission to simplify our architecture and cut out unnecessary complexity.
We found that instead of using Consul, consul-template and haproxy reloads, we could configure haproxy to query Docker DNS directly, by making use of the server-template feature.
Being able to remove Consul and consul-template for loadbalancing made the stack simpler to configure and easier to understand for everyone. What previously consisted of 3 containers and a consul cluster is now just one container and only an overlay network.
Configuring haproxy to use Docker DNS is not that hard and works the same in every Docker container.
resolvers docker
nameserver docker 127.0.0.11:53
resolve_retries 3
timeout resolve 1s
timeout retry 1s
hold other 10s
hold refused 10s
hold nx 10s
hold timeout 10s
hold valid 10s
hold obsolete 10s
Instead of templating all the backend servers in the haproxy configuration file, we can configure them with one line:
backend alfresco
server-template alfresco- 2 alfresco:8080 check resolvers docker init-addr libc,none